Data Engineer
Binnenkort verschijnen nieuwe startdata & prijzen
Data Engineer
Binnenkort verschijnen nieuwe startdata & prijzen
Sector
Data en AI
Leervorm
Hybride leren
Over deze opleiding
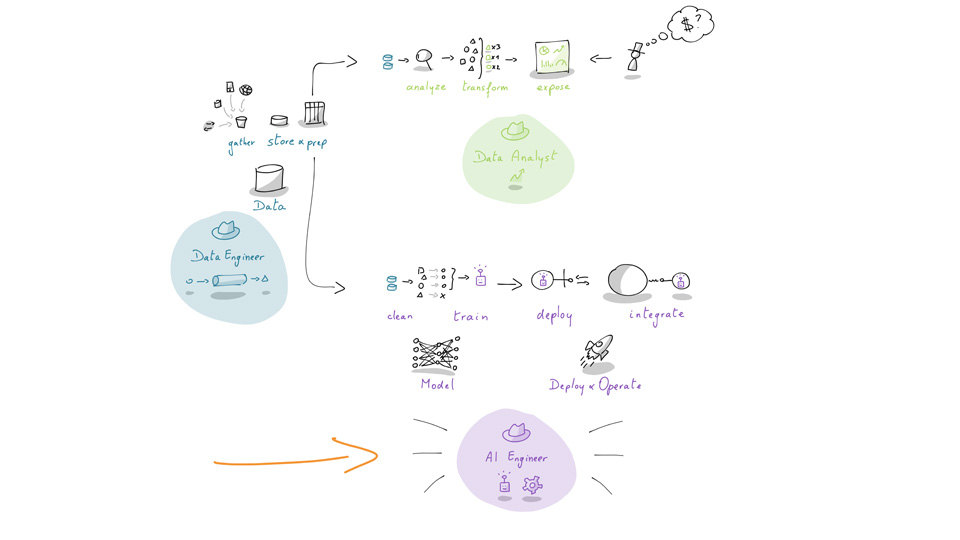
Waarom data engineer worden?
Data engineers zijn één van de meest gevraagde jobs op de markt. In 2022 hebben de meeste organisaties hun eerste data science experimenten uitgevoerd, en zijn ze op weg naar de cloud om daar gebruik te maken van de nuttige services die snel beschikbaar en uitbreidbaar zijn. De taak van een data engineer in deze snel veranderende wereld is om op een kostenefficiënte manier deze services te verbinden en data aan de lopende band te verrijken en ordenen. Het gevolg is dat de vraag naar data engineers enorm hoog is, en dat zal de komende jaren niet verminderen. In tegendeel zelfs. Als data engineer krijg je de kans om op de meest uitdagende projecten te werken bij de meest innovatieve organisaties. Je krijgt de kans om je interesses te volgen en specifieke gebieden van data engineering dieper te verkennen, zoals streaming analytics, het verwerken van enorme hoeveelheden data en het gebruiken van cutting edge technologieën. Jij kiest het bedrijf waarvoor je wil werken en beslist hoe je impact maakt.
Wat doet een data engineer?
Data engineers passen software engineering principes toe op data. De rol gaat verder dan eenvoudigweg data binnen te nemen en te cleanen. Ze bouwen cloud-native architecturen, automatiseren het in productie zetten van data pipelines, waaronder ook machine learning pipelines en AI-modellen en zorgen dat de rest van de organisatie kan uitblinken met hun data producten. Als data engineer ben je verantwoordelijk voor het koppelen, organiseren en ontsluiten van data, zodat anderen in jouw organisatie (of bij de klant) hier effectief gebruik van kunnen maken.
Wat zal je leren?
In deze cursus hebben we een aantal kernonderwerpen uitgekozen waarmee iedere data engineer bekend moet zijn. Voor ieder onderwerp dat we behandelen, hebben we telkens één concrete technologie uitgekozen die veel gebruikt wordt in de praktijk, waarvan we jou de nodige hands-on ervaring zullen geven.
Voor wie
De opleiding vereist:
- Basiskennis Python.
Je wordt verondersteld een functie te kunnen schrijven die uit een datum het jaar haalt, daar 10 bij optelt en terugstuurt naar de plek waar de functie werd gebruikt. - Basiskennis SQL.
Je wordt verondersteld het aantal mensen dat geboren is voor én na 2000 te kunnen bepalen, gegeven een tabel met geboortedata van personen. - Notie van een commandline
Programma
Dag 1 – Introductie tot moderne data platformen en cloud
Deel A: Moderne data platformen (4h)
Vandaag duiken we in de wereld van data engineering. In deze introductie krijg je een overzicht van het huidige data landschap. Welke verwachtingen hebben we vandaag van data en welke technologieën helpen deze in te lossen? We bekijken wat een data platform nu “modern” maakt, wie daar baat bij heeft en welke rol de cloud speelt.
Deel B: Intro tot Cloud Services(4h)
Een basis omtrent cloud is onmisbaar voor een moderne data engineer. Je krijgt een introductie tot de basisconcepten van cloud en gaat er zelf mee aan de slag. We bekijken virtuele machines, container registries, enkele van de vele opslagmogelijkheden, en enkele vendorspecifieke geavanceerde oplossingen, maar ook hoe API’s in zowel de browseromgevingen als in command line interfaces worden gebruikt om snel te kunnen schakelen naargelang de noden van de organisatie.
Vandaag duiken we in de wereld van data engineering. In deze introductie krijg je een overzicht van het huidige data landschap. Welke verwachtingen hebben we vandaag van data en welke technologieën helpen deze in te lossen? We bekijken wat een data platform nu “modern” maakt, wie daar baat bij heeft en welke rol de cloud speelt.
Deel B: Intro tot Cloud Services(4h)
Een basis omtrent cloud is onmisbaar voor een moderne data engineer. Je krijgt een introductie tot de basisconcepten van cloud en gaat er zelf mee aan de slag. We bekijken virtuele machines, container registries, enkele van de vele opslagmogelijkheden, en enkele vendorspecifieke geavanceerde oplossingen, maar ook hoe API’s in zowel de browseromgevingen als in command line interfaces worden gebruikt om snel te kunnen schakelen naargelang de noden van de organisatie.
Dag 2 – Fundamentele werktuigen - git, bash & Linux
Deel A: Basis commandline en Linux (4h)
Vele data applicaties draaien op Linux, een alternatief voor het besturingssysteem Windows of MacOS. Je kan Linux grafisch gebruiken, maar de kracht zit hem vooral in de commandline interface of CLI. In deze module bekijken we welke tools de commandline biedt en hoe ze het leven van een data engineer makkelijker maken.
Deel B: Versiebeheer met git (4h)
Programmeurs delen kennis via code, door deze te schrijven, documenteren en te reviewen. Een belangrijke tool hierbij is de versiecontrole software git, die overgewaaid is uit software engineering. Git betekent het einde van e-mail attachments met daarin je code, al dan niet voorzien van versienummers. We gebruiken deze tool in de rest van deze cursus om code te beheren en samenwerking te vergemakkelijken.
Vele data applicaties draaien op Linux, een alternatief voor het besturingssysteem Windows of MacOS. Je kan Linux grafisch gebruiken, maar de kracht zit hem vooral in de commandline interface of CLI. In deze module bekijken we welke tools de commandline biedt en hoe ze het leven van een data engineer makkelijker maken.
Deel B: Versiebeheer met git (4h)
Programmeurs delen kennis via code, door deze te schrijven, documenteren en te reviewen. Een belangrijke tool hierbij is de versiecontrole software git, die overgewaaid is uit software engineering. Git betekent het einde van e-mail attachments met daarin je code, al dan niet voorzien van versienummers. We gebruiken deze tool in de rest van deze cursus om code te beheren en samenwerking te vergemakkelijken.
Dag 3 – Containerizatie met Docker
Je data applicatie werkt nu, super! Maar ze werkt op jouw laptop… Aangezien het nogal moeilijk is om jouw laptop als productieserver te gebruiken moeten we zorgen dat de applicatie ook werkt op andere machines. In deze module bespreken we Docker, een van de meest revolutionaire technologieën van het afgelopen decennium, om deze uitdaging aan te gaan.
Docker is dé onmisbare tool geworden voor vele software engineers. Als data engineer zal je dit ook tegenkomen, aangezien Docker het packagen en deployen van je oplossing sneller een betrouwbaarder maakt. Docker zorgt ervoor dat je code op iedere machine kan draaien. Je gaat hands-on aan de slag met Docker om zelf te ondervinden wat het voor jou kan betekenen.
Docker is dé onmisbare tool geworden voor vele software engineers. Als data engineer zal je dit ook tegenkomen, aangezien Docker het packagen en deployen van je oplossing sneller een betrouwbaarder maakt. Docker zorgt ervoor dat je code op iedere machine kan draaien. Je gaat hands-on aan de slag met Docker om zelf te ondervinden wat het voor jou kan betekenen.
Dag 4 – SQL analytics met Snowflake en DBT
Eén van de sleutelcomponenten van een goede analytics oplossing is nog steeds een relationele database. Je leert over SQL (inclusief joins en windowing), zet een data warehouse op in Snowflake en bouwt data pipelines met DBT.
Dag 5 – Data Pipelines met PySpark
Wanneer je data te groot wordt of door vele producenten ervan snel op je afkomt, dan zal je als data engineer beroep doen op een framework dat over meerdere machines kan schalen. Spark is een framework dat veel gebruikt wordt en toelaat om data op grote schaal te verwerken. Je gaat in deze module aan de slag met PySpark, zodat je met eenvoudige Python code enorm veel werk kan verzetten.
Dag 6 – Data Orchestration & Project
Deel A: Orchestration with Airflow (4h)
Je hebt een productieve maand achter de rug en hebt plots 3, 4, 5, … 10 batch data pipelines in productie staan. Geweldig! Maar, je zal vast niet 7/7 elke dag om 6:30 de pipeline manueel willen starten. Daarvoor gebruiken we “workflow orchestrators”, zoals Airflow.
Een orchestrator zorgt ervoor dat je optimaal kan inzetten op automatisatie. Hoe vaak moet de pipeline uitgevoerd worden? Wat moet er gebeuren als er iets mis gaat? De meest gebruikte tool hiervoor is Apache Airflow, waarmee je in deze module zelf aan de slag gaat!
Deel B: Capstone Project (4h)
Als laatste opdracht bouw je een heuse data pipeline binnen een modern data platform met echte data, waarbij je al de tools en technieken uit deze cursus combineert. Startende met data van een externe bron, bouw je cleaning- en transformatiepipelines om de data in een data warehouse op te slaan, klaar voor het gebruik van de vele analysten. Vanaf hier kan je een query-gebaseerd dashboard bouwen dat elk uur verse data laat zien!
Dag 7 – Project
Capstone Project - Vervolg (8h)
Dag 8 – Project & Hot topics
Deel A: Capstone Project - Vervolg (4h)
Deel B: Hot topics in Data engineering (4h)
Proficiat! Je bent erin geslaagd om een eigen batch ETL pipeline te bouwen. Meer nog, je hebt hiervoor state-of-the-art tools gebruikt. Nu is het tijd om verder te kijken naar wat de wereld van data engineering – die continu verandert – verder te bieden heeft. We bekijken enkele recente topics die steeds meer aandacht krijgen, zoals streaming, MLOps en data mesh.
Handige links







kmo-portefeuille
Thema: Beroepsspecifieke competentie - KnelpuntberoepDe kmo-portefeuille is een subsidie van de Vlaamse Overheid waardoor je tot 30% van je inschrijvingsgeld kan recupereren. Lees hier hoe de KMO-portefeuille in zijn werk gaat.
Netto verschuldigd bedrag voor:
* middelgrote ondernemingen
** kleine ondernemingen
Lesdata:
8 lesdagen telkens van 9 uur tot 17 uur
ma 6/3 - di 7/3
woe 15/3 - do 16/3
ma 20/3 - di 21/3
ma 27/3 - di 28/3
Locatie: PXL-NeXT - Campus Corda - Lokaal Charles
Koffie, frisdrank en lunch worden voorzien
Contact:
Marijke Sporen
coördinator levenslang leren PXL-Digital
g| +32 (0) 494 63 63 22
e| Marijke.Sporen@pxl.be
Ik wil meer weten
Vond je geen antwoord op je vraag? Stel ze hier aan onze medewerkers.